

Février est un mois court mais la release du mois vous réserve tout de même de nombreuses nouvelles fonctionnalités pour vous permettre d’accélérer toujours plus et améliorer la création de vos applications. Au programme, la conversion automatique de Datagrid1 en Datagrid2, des nouveautés pour les connecteurs OpenAI, REST, DB, la sortie en version publique des Mendix Pipelines et plein d’autres choses… il ne vous reste plus qu’à en prendre connaissance dans la suite de ce billet.
Pour bénéficier de ces nouveautés, vous pouvez télécharger la dernière version de l’outil depuis le marketplace, puis l’installer. Il vous restera alors simplement à ouvrir l’application à mettre à jour avec, et Mx Studio Pro vous proposera alors de la convertir.
Au sommaire de ce billet, présentation des mises à jour côté :
- Création d’applications [App Dev]
- Intégrations [Mendix Connect]
- Les Pipelines Mendix
- Mais aussi divers sujets
- Le mot de la fin et autres ressources
Application Development
Enregistrement automatique à l’exécution
Une minuscule modification, mais qui va surement en ravir plus d’un !
Avez-vous déjà été confronté à cette boîte de dialogue au moment de l’exécution de votre projet dans Studio Pro ?
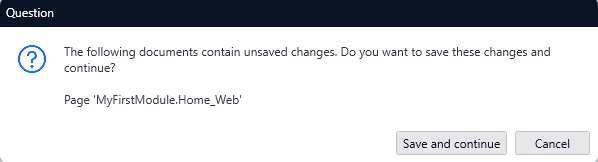
Tout le temps ! me direz-vous 😜. Et bien, désormais, Studio Pro vous permet d’enregistrer automatiquement vos objets lors d’une exécution locale. Cochez simplement la case « Do not ask me again » (*Ne me demandez plus) et ne vous souciez plus jamais de l’enregistrement avant exécution.
Conversion du datagrid 1 en 2
Le widget Datagrid2 est de plus en plus utilisé et plébiscité, mais basculer ses applications existantes utilisant le Datagrid1 peut être fastidieux. Avec cette release, on vous propose de vous faciliter le travail. Pour convertir votre widget Datagrid1, il suffit de choisir l’option en faisant un clic-droit dessus (cliquez-ici pour voir le fonctionnement en vidéo).
NB : certaines fonctionnalités ne peuvent pas encore être converties automatiquement, vous aurez alors un message vous l’indiquant. Nous allons continuer à améliorer cette fonctionnalité dans les releases à venir pour combler cela.
Améliorations du widget Combox Box
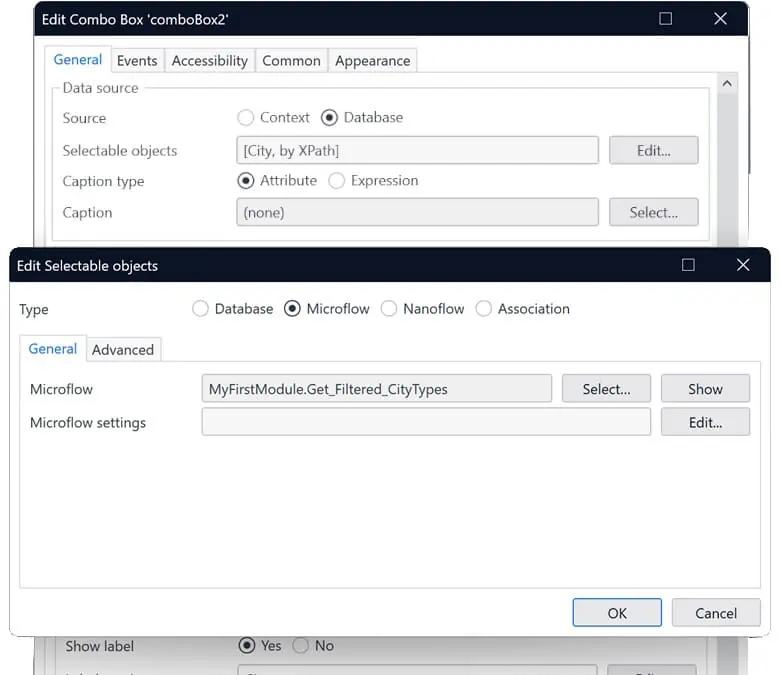
Nous avons ajouté une nouvelle option de source de données pour le widget Combo box, augmentant ainsi sa polyvalence. Avant cette mise à jour, l’affichage d’un ensemble dynamique d’options dans la liste déroulante nécessitait une entité associée avec des données persistantes. Désormais, vous pouvez créer un ensemble dynamique d’options pour n’importe lequel de vos champs de type chaîne, nombre ou énumération, en vous basant sur un micro/nanoflow ou à partir de la base de données, sans qu’il soit nécessaire de créer une association.
Par exemple, vous pouvez récupérer une liste de pays via un service REST et ne stocker que le code du pays au lieu de devoir stocker tous les pays dans votre base de données et d’associer l’entité. Tout comme pour les valeurs associées, vous pouvez personnaliser les options affichées à l’utilisateur tout en stockant la valeur d’un autre attribut. Cette fonctionnalité fonctionne avec les attributs string, integer et enum. Cependant, n’oubliez pas que l’association manquante signifie que le champ d’attribut conservera sa valeur même si l’objet sélectionné est supprimé.
Rich Text v3
Voici une nouvelle version de ce widget qui fournit à l’utilisateur un éditeur WYSIWYG permettant de créer du texte riche et formaté qui est stocké en HTML.
Bien que la plupart des options restent inchangées afin de préserver la compatibilité ascendante, il s’agit d’un tout nouvel éditeur sous le capot. Le précédent widget était basé sur la bibliothèque CKEditor 4, qui a officiellement atteint sa fin de vie. La nouvelle version est basée sur TinyMCE, un puissant éditeur de texte riche à la pointe de la technologie. Par rapport à la génération précédente, il offre un ensemble de fonctionnalités plus riche et une interface utilisateur plus rapide et plus moderne. Nous vous recommandons vivement de mettre à jour votre widget vers la nouvelle version, car une faille de sécurité a récemment été découverte dans la dernière version open-source de CKEditor 4.
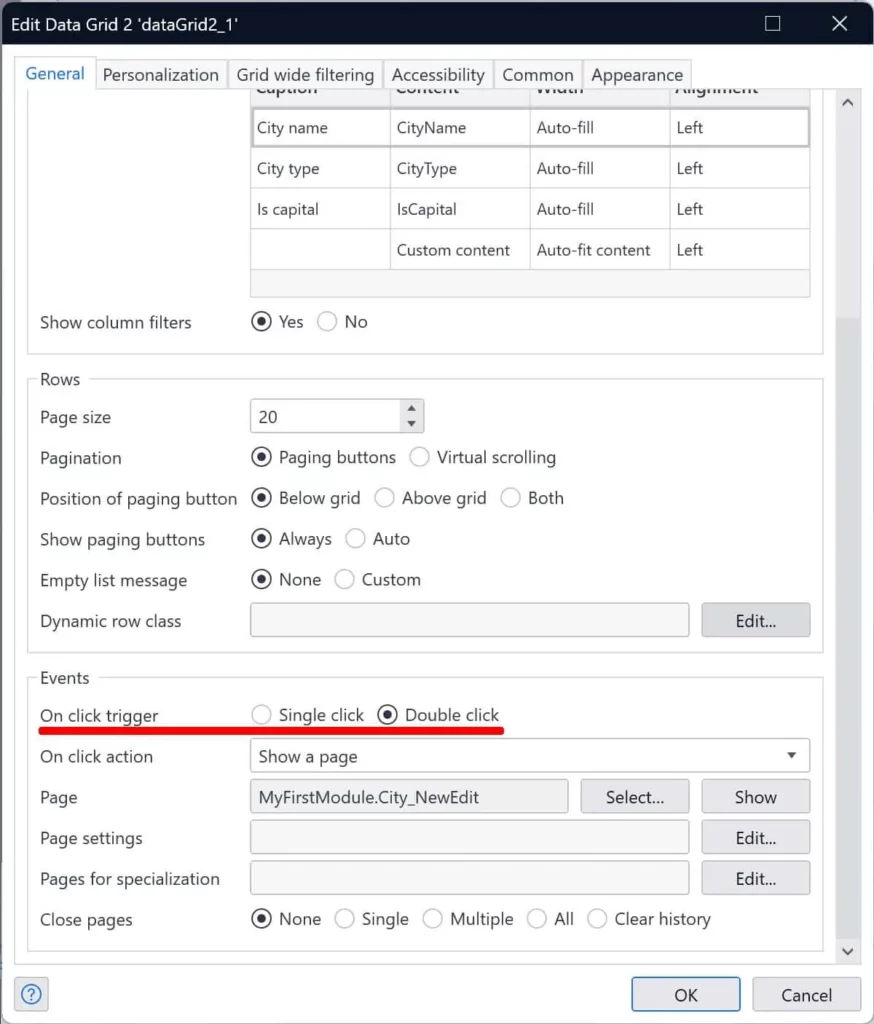
Option double-clic pour le Datagrid2
Le widget Datagrid2 propose désormais la possibilité de déclencher l’événement on-click sur un double-clic au lieu d’un simple-clic. Cela vous permet de configurer à la fois la sélection par clic sur la ligne et l’action sur le clic.
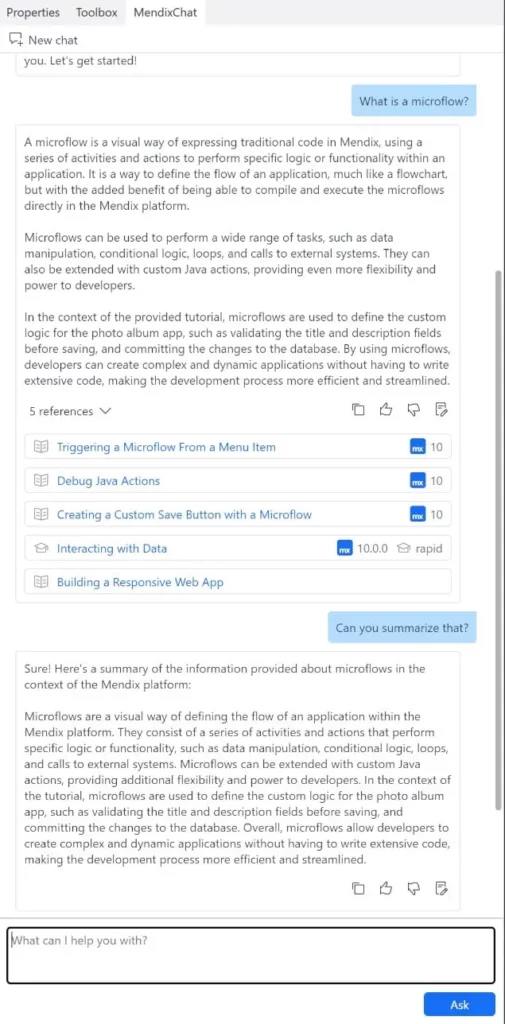
Mendix Chat
Avec Mendix 10.6, nous avons lancé MendixChat en version bêta, notre chatbot de connaissance basé sur l’IA générative pour aider les développeurs Mendix avec leurs questions de conception. Avec Mendix 10.8, nous avons continué à améliorer la fonctionnalité.
En effet, avec cette version, nous avons ajouté une capacité de conversation de base. Désormais, MendixChat permet de poser des questions de suivi basées sur votre question précédente et la réponse que vous avez reçue. Par exemple, vous pouvez demander à MendixChat de résumer la dernière réponse que vous avez reçue en tapant ce qui suit dans le chat : « Can you summarize that? » (*Pouvez-vous résumer cela ?)
MendixChat est actuellement dans une jeune version bêta, attendez-vous donc à des réponses erronées ou incomplètes. Mais aidez nous à l’améliorer en envoyant vos commentaires directement depuis l’interface ! Vous pouvez utiliser MendixChat dans Studio Pro en l’ouvrant via View → MendixChat.
Pour en savoir plus, consultez la documentation sur MendixChat.
Optimisation des performances
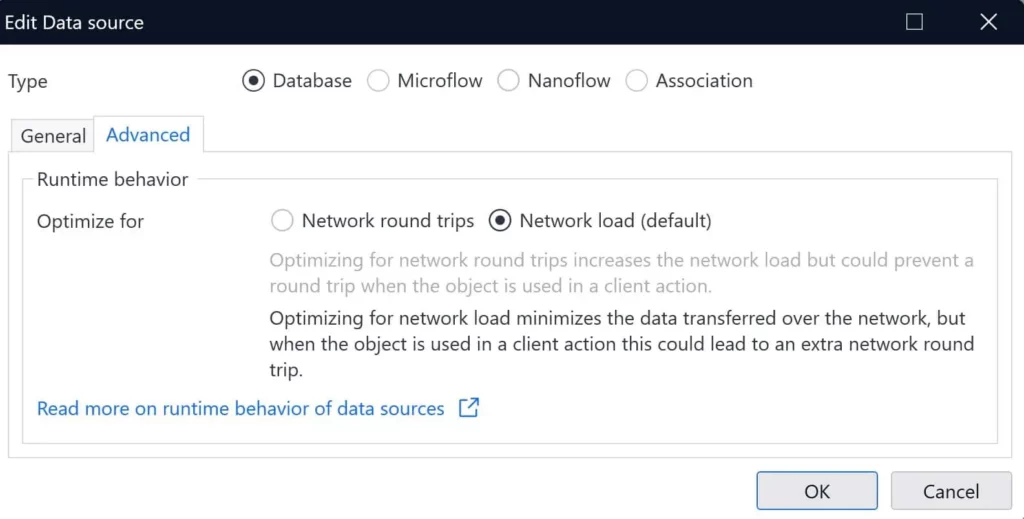
Optimisation des performances concernant la communication client-serveur : objets partiels ou complets?
Le comportement des sources de données lors de l’exécution dépend de la manière dont une page est modélisée dans Studio Pro. Dans certains scénarios, seuls les attributs requis sont envoyés au client, ce qui optimise la charge du réseau. Dans d’autres cas, tous les attributs d’un objet sont envoyés au client, ce qui présente l’avantage d’éviter un aller-retour lorsque l’objet est requis dans une action ultérieure du client. Nous allons maintenant montrer dans Studio Pro lequel de ces cas s’applique à une source de données, et nous allons également permettre de modifier le comportement pour optimiser les allers-retours. Des informations détaillées sur le comportement des sources de données lors de l’exécution sont disponibles ici.
Mendix Connect
Connecteur OpenAI
Nous avons mis à jour le connecteur OpenAI et l’application qui le montre en action pour vous aider à rendre vos applications encore plus intelligentes. Vous allez permettre à vos utilisateurs finaux de faire des recherches intelligentes en exploitant les données existantes et de trouver des éléments similaires (historiques), même s’ils ne savent pas exactement comment ils sont formulés, quelles que soient les abréviations.
Avec l’ajout du mode conversation, vos utilisateurs peuvent poser des questions contextuelles dépendantes des réponses précédentes. Vous pouvez également générer et charger automatiquement des données de démonstration qui impressionneront vos utilisateurs ou vous aideront à tester l’application en demandant explicitement des réponses dans un format JSON prédéfini.
Enfin, nous avons rendu le projet disponible sur Github et nous vous invitons à y contribuer par le biais de pull requests !
Connecteur service REST – consume (beta)
Ce nouveau connecteur permettant d’exécuter des web services REST de manière plus assistée, sorti avec la 10.6 et auquel nous avons dédié un billet est agrémenté, avec cette nouvelle version, du support des opérations de type PUT. Avec cet ajout, vous pouvez commencer à utiliser le Consumed REST Service pour la plupart de vos appels REST.
Actions OData
Vous pouvez désormais publier des actions OData en utilisant des paramètres qui ne sont pas exposés en tant que ressources REST dans votre API. Lorsque vous utilisez ces paramètres, ils seront représentés dans l’application client comme des NPE (entités non persistantes) définies par le service. Cela vous indiquera que ces entités externes peuvent être utilisées pour fournir des inputs ou des outputs aux actions externes, mais qu’elles ne représentent pas un ensemble de données pouvant être interrogé.
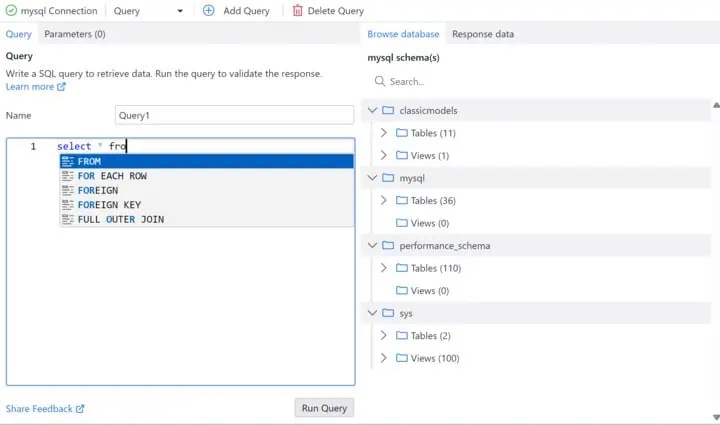
Amélioration de l’édition SQL pour le connecteur de base de données
Les améliorations apportées ce mois-ci au connecteur de base de données externe (également sorti avec la 10.6 et pour lequel nous avons dédié un billet) vous permettront d’écrire des requêtes plus rapidement. La taille de l’éditeur a été augmentée pour simplifier l’écriture de requêtes plus conséquentes, et la vue de la base de données est maintenant organisée par schéma, ce qui vous aide à vous concentrer sur le schéma pertinent. Enfin, l’autocomplétion dans l’éditeur vous permet de sélectionner des tables et des vues.
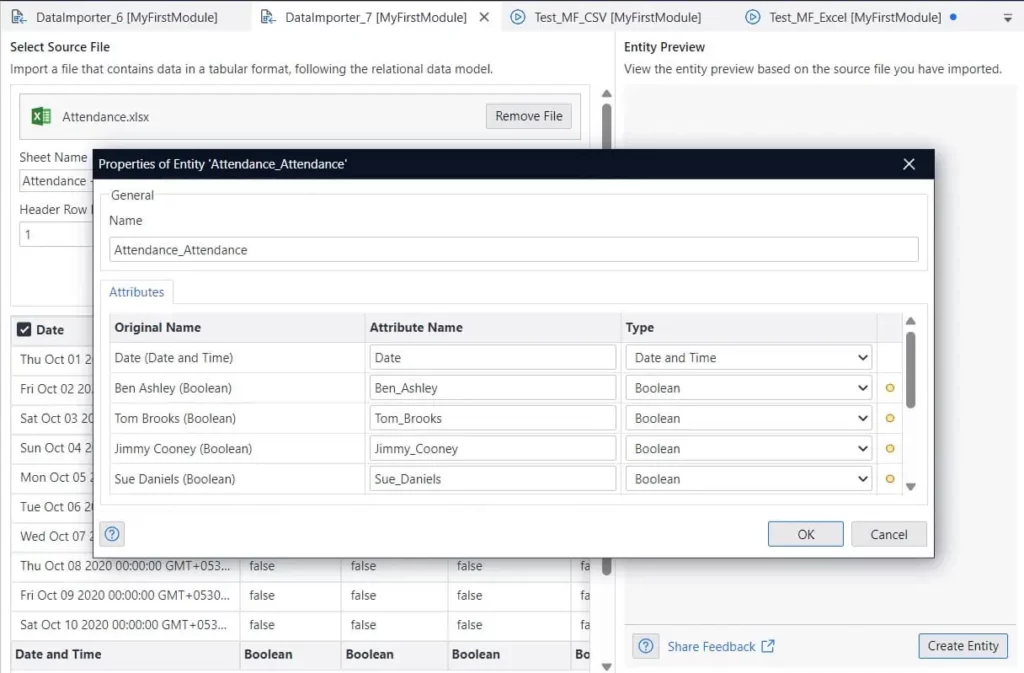
Modification du type de données des fichiers Excel et CSV
Avec cette release, nous avons rendu les types de données Excel et CSV modifiables lorsqu’on utilise le composant Data Importer sortie avec la version 10.6. Vous pouvez désormais modifier les types de données utilisés dans un format si la définition initiale est incorrecte.
Les pipelines Mendix
Est-ce que vous consacrez beaucoup de temps et d’efforts au packaging et au déploiement de vos applications Mendix ? Vous faîtes ces déploiements en dehors des heures ouvrables ? Ce ne sera plus le cas ! Mendix Pipelines est disponible en version bêta publique pour vous y aider ! Vous pouvez automatiser tout cela facilement, sans avoir besoin de savoir-faire en matière de devops !
Comment cela fonctionne ? La fonctionnalité Pipelines, vous permet de concevoir vos propres processus de build et de deploy à l’aide d’un ensemble d’étapes préconstruites, configurables et faciles à utiliser. Après avoir conçu vos pipelines, ils s’exécuteront automatiquement. Il n’y a plus qu’à vous détendre.
Prenons un exemple. Disons que vous voulez « builder » et déployer automatiquement l’environnement de test à chaque fois qu’un nouveau commit (teamserver push git) est fait sur la branche Main line. Voici ce que vous devez faire :
Conception d’une pipeline
La vidéo disponible ici reprend les étapes ci-dessous :
- Accédez à la page Pipelines dans le portail des développeurs. (NB : tous les utilisateurs dont le rôle comporte l’option « Cloud Access » pourront afficher cet onglet)
- Concevez un nouveau pipeline. Pour accélérer le processus, commencez la conception à partir d’un « template ». Un modèle est livré avec une séquence logique prédéfinie d’étapes – Démarrer le pipeline, Vérifier, Construire, Publier et Déployer. Les étapes peuvent être modifiées, ajoutées ou supprimées selon vos préférences.
- Développez l’étape « Start pipeline » et spécifiez une expression de branche. Un nom de branche unique peut être choisit ou une expression telle que « Main* » peut être spécifiée, ce qui déclenchera le pipeline sur les commits de toute branche commençant par « Main ». Dans le cadre de cet exemple, spécifiez « Main ».
- Examinez la configuration de chaque étape et ajustez-la si nécessaire. Par exemple, dans l’étape de déploiement, assurez-vous que l’environnement est défini sur Test pour le déploiement dans l’environnement Test.
- Une fois que vous avez terminé, cliquez sur « Save & Activate ». En tant qu’action unique, fournissez votre jeton d’accès personnel et votre clé API. Ces informations d’identification spécifiques à l’utilisateur sont utilisées pour exécuter des pipelines avec votre rôle et vos autorisations.
Surveillance de l’exécution de ses pipelines
Dès son activation, la pipeline s’exécutera automatiquement en fonction des conditions définies à l’étape Start Pipeline.
Comme vous pouvez le voir dans cette vidéo, toutes les exécutions de pipeline sont visibles sous l’onglet « Runs » (*Exécutions). Chaque exécution peut être consultée pour en voir le détail. En cas d’échec de l’exécution, l’utilisateur qui a déclenché la pipeline en est informé par e-mail et par l’icône de notification sur le portail.
Pour plus d’informations sur cette fonctionnalité, référez-vous à la documentation.
Rmq : Mendix Pipelines est en version bêta publique. Elle est actuellement disponible pour une utilisation illimitée avec toutes les applications Mendix Cloud sous licence. Des limitations d’utilisation pourront être mises en place à l’avenir.
Un grand merci à tous ceux qui ont participé aux sessions de découverte et de validation. Votre contribution a été inestimable pour façonner Pipelines.
Mais aussi…
Support de Java 17
Bien que nous travaillions toujours à la prise en charge de Java 21 dans les mois à venir, il est déjà possible d’utiliser Java 17 à partir de Mendix 10.8. Le passage à une nouvelle version de Java vous permettra d’utiliser une version supportée avec des correctifs de sécurité pour les années à venir. À ce stade, nous recommandons d’attendre le support de Java 21, qui est prévu pour Mendix 10.10 et sera rétroporté à 10.6, afin d’éviter d’avoir à migrer deux fois.
Pour exécuter une application avec Java 17, vous pouvez changer la version Java de votre application en choisissant une version dans les paramètres de l’application sur l’onglet Runtime. Pour l’instant, vous devrez pointer vous-même vers un nouveau JDK, ce dont nous nous occuperons dans une prochaine version. Nous vous conseillons de tester votre application après avoir modifié la version de Java afin de détecter à temps les changements de comportement mineurs.
Pour plus d’informations sur l’impact et les versions LTS/MTS précédemment publiées qui obtiendront le support de Java 17 et/ou Java 21, veuillez consulter cet article de blog 🇬🇧.
Le mot de la fin et autres ressources
Vous retrouverez la release note de la version 10.8 dans la documentation Mendix, détaillant également un ensemble de petites améliorations et corrections. Et ici la liste de toutes les releases notes, vous n’avez plus qu’à choisir votre version 😉.
Retrouvez également le billet 🇬🇧 de cette release (et la vidéo 🎞️ 🇬🇧 de 5 minutes)… ou la liste de tous les billets 🇬🇧 concernant des releases.
Happy Mx-low-coding !
Pas encore de commentaire